Privacy
How we have optimized ZK operations to under one second
Jun 20, 2024

AI Summary

Blockchains offer many benefits compared to centralized finance: transparency, the removal of intermediary costs, additional security from hacks, and so on. However, in most blockchains, privacy really isn’t one of these benefits.
Web3 privacy is far from solved
In fact, a typical blockchain offers worse privacy than transferring money via a bank. This is because at the heart of its design, there is a consensus protocol, in which all the computers that are building the blocks need to process who is sending tokens to whom, in order to agree on the correct balances and so on. This means that once any third party comes into possession of your wallet address, that third party can easily monitor all your transactions. And learning someone’s address is not difficult at all. For example, if you buy flowers for 0.0000037 bitcoin (BTC) from a certain florist on a specific day, a third party can just scan the public transaction record for that day and if there is just one transaction that matches this description, identify your wallet address.
Making such transactions private is difficult as the nodes running the chain would need to agree on the transactions without actually “seeing” them. But it can be done with zero-knowledge (ZK) proofs.
At Aleph Zero, we are building our new EVM layer using the Arbitrum Orbit stack and custom privacy features that are competitively fast and cryptographically secure. As part of the design, we will offer the broader EVM community the ability to send transactions whose details cannot be seen or linked together by other users. Thanks to idOS Network and integration with Lukka, we will also include effective mechanisms to prevent our platform from being used for illicit activities, aiming to ensure optimal user compliance with applicable laws. We call our privacy design zkOS by Aleph Zero in an effort to unify the naming of various privacy-enhancing technologies within the ecosystem, such as Liminal and Shielder, as well as the upcoming Privacy-as-a-Service offering, under a collective umbrella.
Important!
In the broader web3 space, ZK is primarily associated with server-side Ethereum scaling (ZK rollups, ZK EVMs, etc.), which does not have much to do with privacy. Today, the most popular privacy designs are based largely on Trusted Execution Environments (TEEs) as a method of achieving confidential computation, meaning that users’ data is stored “inside” of specialized hardware chips (the most popular being Intel SGX) that are typically hosted on network’s validator nodes. While this approach has a number of advantages, it relies on significant trust assumptions from the perspective of where the encrypted data actually resides – i.e. outside of users’ control.
Almost immediately after beginning our work on the privacy features, we became concerned about the user experience. ZK proofs require long computations, potentially lasting minutes – so anyone who would use a “default” implementation would need to wait for so long, that the benefits of privacy would be overshadowed by a lack of sufficient levels of usability. So, before we committed to any design choices, we researched what could be done to minimize the computational strain on the device used to make the transactions.
We are more than satisfied with the outcome. We benchmarked the core cryptographic operation required to make private transactions and confirmed that it runs within seconds even on slower desktop devices. We’ve actually built a website that allows you to run the benchmark yourself. We encourage you to try it out and share your results!
Run the benchmark on thatfast.alephzero.org
The structure of this post is as follows. In the next section, we give a high-level summary of our results. Then, in the second part of this post, we present our exact numbers, together with a technical description of the optimizations behind them.
Achieving subsecond client-side ZK proving – the overview of our improvements
Let’s first explain by example how ZK helps the case for an optimal web3 privacy design. Suppose that a user wants to make a private transaction. ZK proofs allow the user to prove that they’re changing their account state correctly without revealing the details of the update action. This proof is sent to the chain nodes, which run cryptographic verification. This verification, if successful, commands the nodes to accept the change into their records. And because it’s zero-knowledge, all that the nodes learn is that the proposed change is correct – neither the user’s wallet address nor the account balance is revealed in the process.
There is a complication, though. The purpose of ZK proofs is to keep the user’s data on their device (smartphone, tablet, laptop, desktop computer) and only let the proofs be sent outside. In practice, this means that the proofs must be prepared on that device, without accessing any cloud computing power. Unfortunately, as we mentioned before, the preparation of these proofs takes a lot of processor time, which puts a strain on the majority of devices that are currently available on the mass markets. The sole fact that this computation is happening on the user’s side makes it that much more inconvenient. Unoptimized, the running time of a single wallet operation could easily go into minutes, which would make it completely impractical and not suitable for a broader audience. An additional difficulty is that we need to run these computations in a browser (like Chrome) to ensure broader distribution, which does not offer as direct access to the CPU as regular apps.
This means that before we started working on Aleph Zero’s zkOS, we needed to ensure that we could compute ZK proofs in a time that was acceptable – or even desirable – from a user experience perspective.
We realized this by setting up a benchmark that simulates actual web browser conditions for the code we’re testing. In our benchmark, we created a wrapper for Halo2 — a state-of-the-art ZK proving system — so that it could run inside a web browser. Then, our team wrote code for the core operation of our wallet: producing a zero-knowledge proof of membership of a note in a Merkle tree. We measured the time to produce a single such proof. Our first results were above 15 seconds – better than a generic “couple of minutes”, but still not good enough for an average user.
In consequence, we adjusted Halo2 parameters, established a baseline of 6500 milliseconds, and proceeded to optimize that.
We’ve sped up proof generation with multithreading, optimized the arity of our Merkle trees, replaced our hash function with Poseidon2 – one of the newest ZK-friendly hash functions, described in a 2023 paper – and optimized its implementation.
Results
We reduced the time to produce a ZK proof to 1400 ms on a ThinkPad X1 Carbon Gen 11 with an Intel Core i7-1365U CPU. We have also measured this time on faster laptops and learned that we can achieve results below 1000 ms: 420 ms on a MacBook Air with an M3 processor and 790 ms on an ASUS M16 with an Intel i9-12900H.
These numbers make us confident about the competitive performance of zkOS privacy features.
Here, we conclude the high-level part of this post. We encourage you to try out our testing website again. And if you’d like to learn more about the technical details, continue to the second part!
Our setup
Let’s first summarize our technical stack and the exact setup in which we obtained our numbers.
The Halo2 proving framework
Producing zero-knowledge proofs involves some heavy mathematical machinery, so it is usually not done by hand. Instead, one of the many proving frameworks is used. We decided that for our purposes the best choice is Halo2 with a KZG commitment scheme. This is one of the fastest frameworks in which the proving system uses a so-called trusted setup. Its excellent performance comes at a price, though: Halo2 is difficult to learn, and preparing proofs with it takes much more developer effort than when using alternatives like Noir, Risc0, or SP1. To get a basic understanding of Halo2, see this blog post.
Benchmark setup
To accurately replicate the in-browser experience, simply running Halo2 circuits written in Rust is not sufficient. This would be an appropriate benchmark if we wanted our desktop users to install a dedicated app on their desktop, which of course is not an optimal user experience (UX). For the most undisrupted UX, private wallet operations should be accessible either directly from a browser or from a browser extension similar to MetaMask. One of the modern solutions to execute computation-heavy code in these environments is called WebAssembly (WASM). So, we set up our benchmark to compile Halo2 into WASM. Then, we measured proving times in Chromium using native API.
Note that our code can easily be run on mobile devices as well.
Finally, let’s describe the exact mathematical setup. For the sake of completeness, we use some terms that might be unclear at this point but will be explained later. In our benchmark, we use Halo2 to create a ZK proof of membership of a leaf in a Merkle tree with at least 236 leaves. The benchmarking suite is configured to measure the time to produce the proof. For hashing, we started with the Poseidon hash function, which is well-established in ZK applications. Specifically, we’ve used PSE’s Halo2 Poseidon chip implementation.
Our benchmark measures other metrics besides proving time, such as verification time and proof size. Since the verification time and proof size results looked good from the beginning, we kept our focus specifically on shortening proving times.
Unless mentioned otherwise, all the results in this post were measured on a ThinkPad X1 Carbon Gen 11 with an Intel Core i7-1365U CPU.
Baseline result
Recall that our first proving times were above 15 seconds with default settings of Halo2 parameters. Even after adjusting these parameters for circuit size, our proving time amounted to 6500 ms. We set out to improve this number.
Mathematics: proofs, circuits, and trees
We need to explain some cryptographic concepts to properly tell the story of our optimizations.
Zero-knowledge proofs
The design of a private wallet involves many operations, as described in our documentation. Luckily for us, all these operations have a single main bottleneck: producing a zero-knowledge proof of membership of a note in a Merkle tree, which we’ll call a ZK membership proof for short. Allow us to explain this concept step by step.
Informally, a zero-knowledge proof is a way for one party to prove their knowledge of certain information to another party without revealing that information. This non-revealing property is guarded by strong mathematical guarantees. We offer a broader explanation of ZK proofs here.
Typically, in a ZK setup, we distinguish between on-chain storage and computations, which are visible to everyone, and client-side computations, executed by the user and on their own device. Private user data never leaves the client side (i.e. your device), only ZK proofs of the correctness of the state of the data. This protects secret details, like the user’s account ID, from being seen by other blockchain users.
Merkle trees
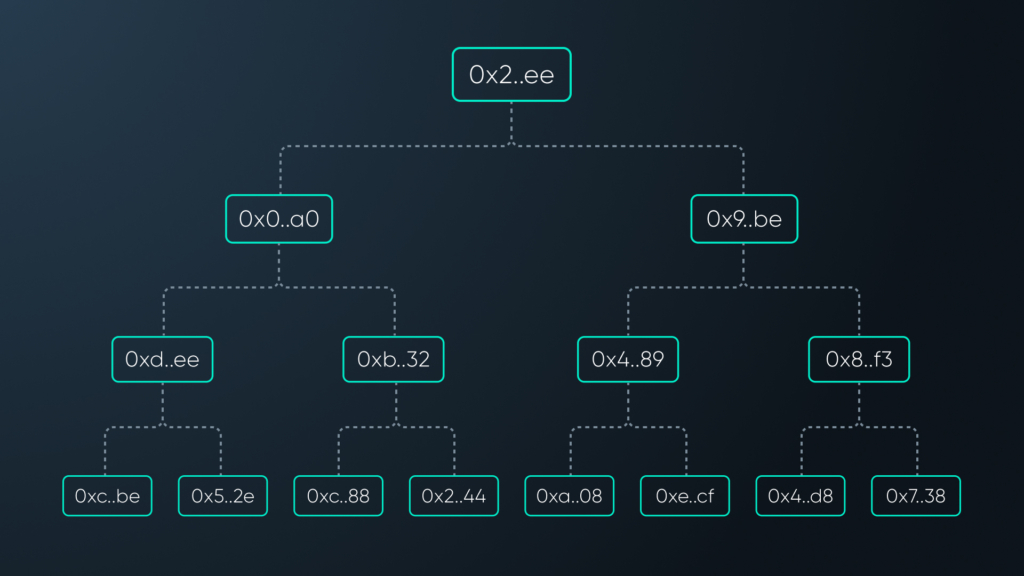
A Merkle tree is a tree data structure that keeps hashes. More formally, it is a rooted tree in which every node stores a single hash, every internal node has the same number of children, and all leaves are on the same level. Each hash is an element of a fixed finite field. The leaves store hashes of notes representing account states, and internal nodes store hashes of hashes stored in their children. The tree is usually publicly kept on-chain. In contrast, account states themselves are private, and it is not practically possible for a third party to get from a leaf hash to the corresponding account state, because hashing is a one-way process. Only the party who knows the account state can produce a hash of that state. This means that nobody knows the full state represented by the tree – the knowledge is distributed.
Every transaction uses a new leaf, so the tree must be large enough. In our benchmark, we fixed the number of leaves at 236, which we deem sufficient for practical purposes.
Zero-knowledge membership proofs with Halo2
Informally, a ZK membership proof is a zero-knowledge proof that a user owns a note in a Merkle tree. In practice, this proof is made of all the hashes on the path from the leaf representing the note to the root of the tree, all the hashes of the siblings of the nodes of the path, and computation traces that guarantee that each node in the path is indeed the hash of its children.
The production of a ZK membership proof in Halo2 involves populating a 2D array called the Plonk table with the mentioned hashes and the computation traces. The traces are just intermediate values for every application of the hash function.
So far, the Plonk table is just an array. To give it meaning, we need to define a set of constraints. These constraints must enforce the correctness of all hashes and computation traces that were put in the Plonk table. There are some special rules to define these constraints that we will not cover here. The point of these constraints is the following: whenever someone populates the Plonk table and satisfies all the constraints, they own an account in the exact Merkle tree that is stored on-chain. This is because the hash of their account state is put at the beginning of the Plonk table, and from this point onwards everything is checked by the constraints. Hashing the leaf hash together with the hashes of its siblings gives the hash of the leaf’s parent, also stored in the Plonk table. Next, the hash of the parent, together with the hashes of the parent’s siblings hashed together, give the hash of the parent’s parent – and so on, up until the root, whose hash is constrained to be equal to the Merkle root hash stored on-chain.
There is a bit more terminology here. The hashes and computation traces put in the Plonk table are called witnesses. The mathematical representation of all the constraints is called a circuit. Circuits take the witnesses as input and accept this input only if all constraints are satisfied.
After the Plonk table is populated, still on the user’s side, Halo2 performs a special computation: proof generation. It converts the populated Plonk table together with the circuit definition into cryptographic evidence (excellently explained in this series of lectures) that the user indeed correctly populated this table. This evidence is our ZK membership proof.
Producing such a proof requires vastly more processor time than just filling in the Plonk table. The reason is that it involves several heavy operations on polynomials and elliptic curves. As a result, the time required for this step can easily go into seconds or even minutes. This is the exact step that determines the duration of our private wallet operations and precisely what we focus our optimization efforts on.
Verification step
To complete the description of our ZK protocol, we need to explain what happens on-chain once the user submits the ZK membership proof.
From a circuit, Halo2 produces an algorithm called a verifier. The role of a verifier is to take the ZK membership proof as an input and output whether it is correct. In our case, this step is much more efficient than client-side proving: around 50 ms. Since there was no need to optimize this number yet, we won’t go into the details of verifiers in this post.
Optimizations
In our benchmarking suite, we implemented a Halo2 circuit that takes user-provided witnesses as input and ensures that their values encode an actual path in a Merkle tree. We wrote code that generates correct witness values, and Halo2 provided proving routines together with a verifier and some necessary cryptographic keys.
Recall that we started with a binary Merkle tree with 236 leaves and the Poseidon hash function. As we discussed earlier, this gives us a baseline proving time of 6500 ms.
Parallelizing proof generation
First, we needed to make sure that our benchmark runs in parallel. We achieved that with the help of Web Workers and native support of rayon in Halo2, which we extended to run in a browser using wasm-bindgen-rayon. This immediately decreased the running time of our benchmark to 3700 ms.
Adjusting Merkle tree arity
The arity of a Merkle tree is the number of children every internal node has. In our baseline implementation, it is equal to 2, but this is not a must at all. We can choose any arity we want as long as we make sure to support at least as many leaves as before. Specifically, we can choose arity A if we adjust the height of the tree to ⌈logA 236⌉. So for A = 3, 4, 5, the height decreases from 36 to 23, 18, and 16, respectively.
Why would we want to do that? Well, it turns out that Merkle trees are one of the use cases Poseidon is designed for. Note that hashes in a Merkle tree always take as input a tuple of field elements with the tuple’s size equal to the tree’s arity. Now, instead of offering just a generic input of a stream of bytes, Poseidon can be configured to take a fixed-size tuple of field elements as input. This allows the hashing to be handled more efficiently.
In our case, if we denote the proving cost of a single Poseidon hash computation of an A-tuple by CP(A), then the proving cost of the entire membership proof is roughly proportional to CP(A) ⋅ ⌈logA 236⌉. The optimal A is quite unclear at this point.
So, the next thing we did was rewrite our code to support arbitrary arity. This involved changing our Merkle tree implementation. Then we tested various values of A. The results are as follows:

The best-performing arities are 4 and 8. Arity 4 is actually the Merkle tree arity recommended for ZK membership proofs in the original Poseidon paper. There might be some noise in this chart, which is expected, as changes in arity influence Halo2 parameters in a non-continuous way. Looking just at the presented numbers, arity 8 is the best, but in practice there might be some tradeoffs to consider, like gas costs.
We are down to 2150 ms.
Digression: performance optimizations in Halo2
Before we describe our other optimizations, we should explore how to optimize the proving time of a Halo2 circuit.
When optimizing any program’s running time, things usually come to mind like big O complexity, the number of heavy arithmetic operations, memory locality, perhaps loop unrolling, and so on. In our situation, however, these ideas can only apply to the process of filling in the Plonk table, unless we’d like to optimize the Halo2 code itself. Filling in the Plonk table does not take much time compared to the library operations that come later. So the real question is, how do we decrease the time Halo2 needs to produce the proof?
We’ll not go into the why but we’ll summarize some of the factors that influence the proving time. The first one is the number of rows in the Plonk table. The smaller it is, the smaller the polynomials Halo2 works on can be, and so the prover time.
Reducing the number of rows does not decrease the prover time in a continuous manner, though. What matters is the smallest k such that the number of rows fits under 2k. So to give an example, 600 rows and 900 rows both require k=10 and lead to similar prover times, whereas going below 512 reduces k to 9 and should have visible performance benefits. This k is actually one of the circuit’s parameters and needs to be declared in advance.
The second important factor that contributes to the proving time is the maximum degree of the constraints in the circuit. Each constraint is actually just a multivariate polynomial that takes some values from the Plonk table as input and is required to evaluate to 0. The degree of a constraint is the degree of that polynomial. So, for example, raising elements of the Plonk table to high powers inside the constraints increases the maximum constraint degree.
These are not the only mechanisms that influence the proving time, but let’s stop here. For our discussion, these are the most important ones.
Switching to Poseidon2
Let’s get back to optimizing our circuits. We had one more thing to try. Assuming arity 4, our Merkle proof is essentially a composition of ⌈log4 236⌉ = 18 copies of the so-called Poseidon chip, which is a Halo2 term for a piece of logic that “computes” the Poseidon hash. This chip is the bottleneck for our proving time. We wrote “computes” in quotes because what the chip does is not just regular computation – it also provides a computation trace for the Plonk table and constraints that verify the trace’s correctness. Later, the constraints become a part of the circuit.
One important thing to note is that our choices for a hash function that can be used inside a ZK proof are somewhat limited. A function like SHA can be very costly to “compute” inside of a circuit. For this reason, we chose Poseidon for our Merkle proof, however, just a year ago a new version of Poseidon was published, called Poseidon2. One of its design goals is specifically to improve proving performance in setups like Halo2.
The effort paid off. After implementing a Poseidon2 chip based on PSE’s Poseidon implementation, optimizing the chip to reduce the number of rows in the Plonk table, and applying some other smaller optimizations, we obtained better proving times:

As Poseidon2 doesn’t support all arities, you may notice missing data points for several of them. This has no practical relevance as the available arities are sufficient for our needs.
Choosing arity 7 brings us down to 1750 ms.
Fine-tuning Poseidon2
To get a broader understanding of both Poseidon and Poseidon2, see this post.
For now, suffice it to say that Poseidon2 hash is obtained by applying around 60 computation rounds to a state tuple of somewhere between 2 and 16 field elements, depending on the arity. A single computation round consists of adding some precomputed constants, applying the so-called nonlinear layer, and multiplying the state by a matrix. The nonlinear layer is simply applying the map x ↦ xα with α=5 to a single element of the state.
The authors of Poseidon allow the possibility of using other nonlinear layers. But, at first glance, this incurs a greater cost, because the remaining choices for α are greater than 5, and this directly translates to a higher maximum degree of the circuit. Yet, it is a bit more subtle: the parameter α is a factor in the security analysis that determines the number of rounds. In our instantiation, going from α=5 to α=7 decreases the total number of rounds from 65 to 55, which reduces the number of rows in the Plonk table. In other words, we reduce the proving time while keeping the same level of security.
In our benchmark, this modification decreased the parameter k of our circuit, which resulted in a very visible gain: we reduced the proving time to 1380 ms!

Final remarks
We presented our results as benchmarked on a moderately fast laptop. We also ran the same benchmark on faster computers and obtained subsecond times:
- MacBook Air with a M3 processor: 420 ms,
- ASUS M16 with an Intel i9-12900H processor: 790 ms.
We also point out that there are other optimization goals: curve security, verifier time, proof size, and gas costs. We keep track of them as well.
Finally, the Poseidon2 paper describes a promising optimization direction that we haven’t tested yet. We will definitely try it out!
Acknowledgements
This project was a joint effort of our ZK team and Piotr Rosłaniec, who joined us specifically for this task. We extend our deep gratitude to Piotr for his invaluable contributions, such as developing the benchmarking suite, integrating Halo2 code with JS, and providing expert advice on multiple topics. Piotr, we couldn’t have done this without you!
